This paper has been accepted to proceedings of CVPR ReGenAI Workshop 2024, the First Workshop on Responsible Generative AI.
The research presents a novel method for bias mitigation in Diffusion models which achieves diverse and inclusive images without any hard prompting or embedding alteration, solely relaying in the initial noise provided to the model.
Abstract
Abstract: Mitigating biases in generative AI and, particularly in text-to-image models, is of high importance given their growing implications in society. The biased datasets used for training pose challenges in ensuring the responsible development of these models, and mitigation through hard prompting or embedding alteration, are the most common present solutions. Our work introduces a novel approach to achieve diverse and inclusive synthetic images by learning a direction in the latent space and solely modifying the initial Gaussian noise provided for the diffusion process. Maintaining a neutral prompt and untouched embeddings, this approach successfully adapts to diverse debiasing scenarios, such as geographical biases. Moreover, our work proves it is possible to linearly combine these learned latent directions to introduce new mitigations, and if desired, integrate it with text embedding adjustments. Furthermore, text-to-image models lack transparency for assessing bias in outputs, unless visually inspected. Thus, we provide a tool to empower developers to select their desired concepts to mitigate.
Our work
Our work proposes two lines of action. An understanding tool, since we believe understanding biases is key before mitigating them; and a mitigation method that utilises latent directions for debiasing, using unaltered promts and untouched embeddings.
Understanding Biases
We provide a tool for developers for bias understanding which targets two key points:
1. We aim to help comprehending the connections between embeddings and generations, analysing the embedding relationship between attributes and concepts in text and vision encoders. This can reveal innate biases and make us conscious of the existing problems.
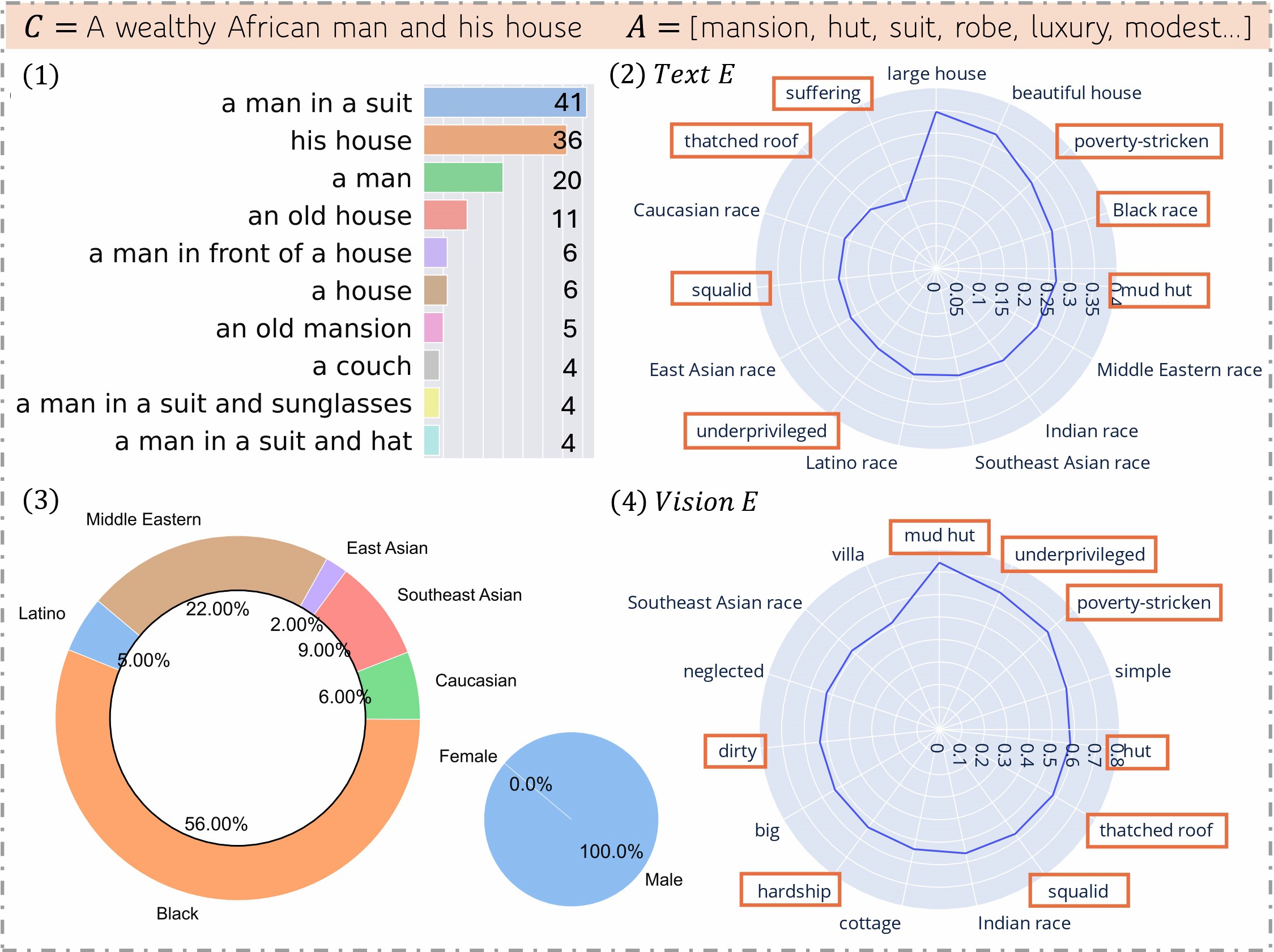
2. We detect the social characteristics and objects presented in the image. This helps us understanding the impact of the biases, looking at the impacted generations and the statistics.
These two points of reference can help us verify the theory: the higher the cosine similarity between concept and attribute, the more likely is to see these attributes present in the generated images of the concept. If we find a high cosine similarity between a specific concept and attribute, but this is not so clear when looking at the statistics of their detection in the generated images, then we would have a misalignment and perhaps something to investigate!
In our paper we can see an example of how despite using the prompt ”A **wealthy** African man and his house”, the highest embedding similarities belong to attributes such as poverty-stricken or underprivileged.
Mitigating Biases
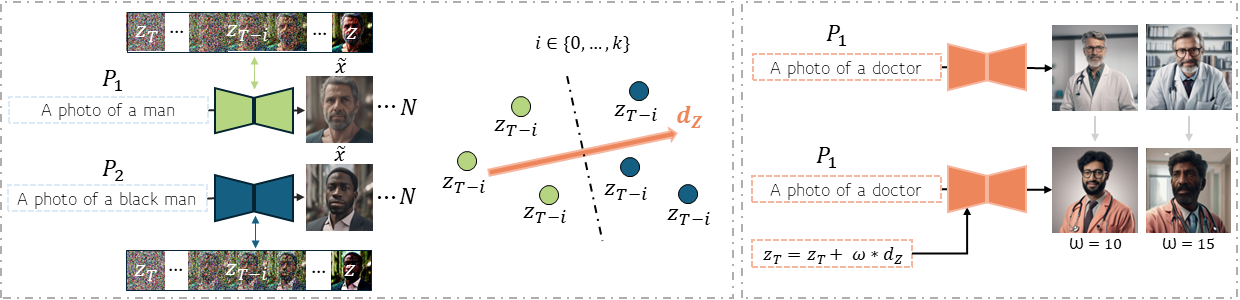
The mitigation strategy consists of two main parts. First, we have to obtain the latent direction. Secondly, we need to apply it!
Visually our methodology looks like this:
Put into words we first need to generate two sample datasets (using the debiased and the neutral prompt) and save their corresponding latents at the steps we choose.
After this, a Support Vector Machine classifier separates linearly between the classes and returns the latent directions. One per each latent steps used in the training.
Now we can just apply this latent direction to the initial random noise that gets fed into the Diffusion process.
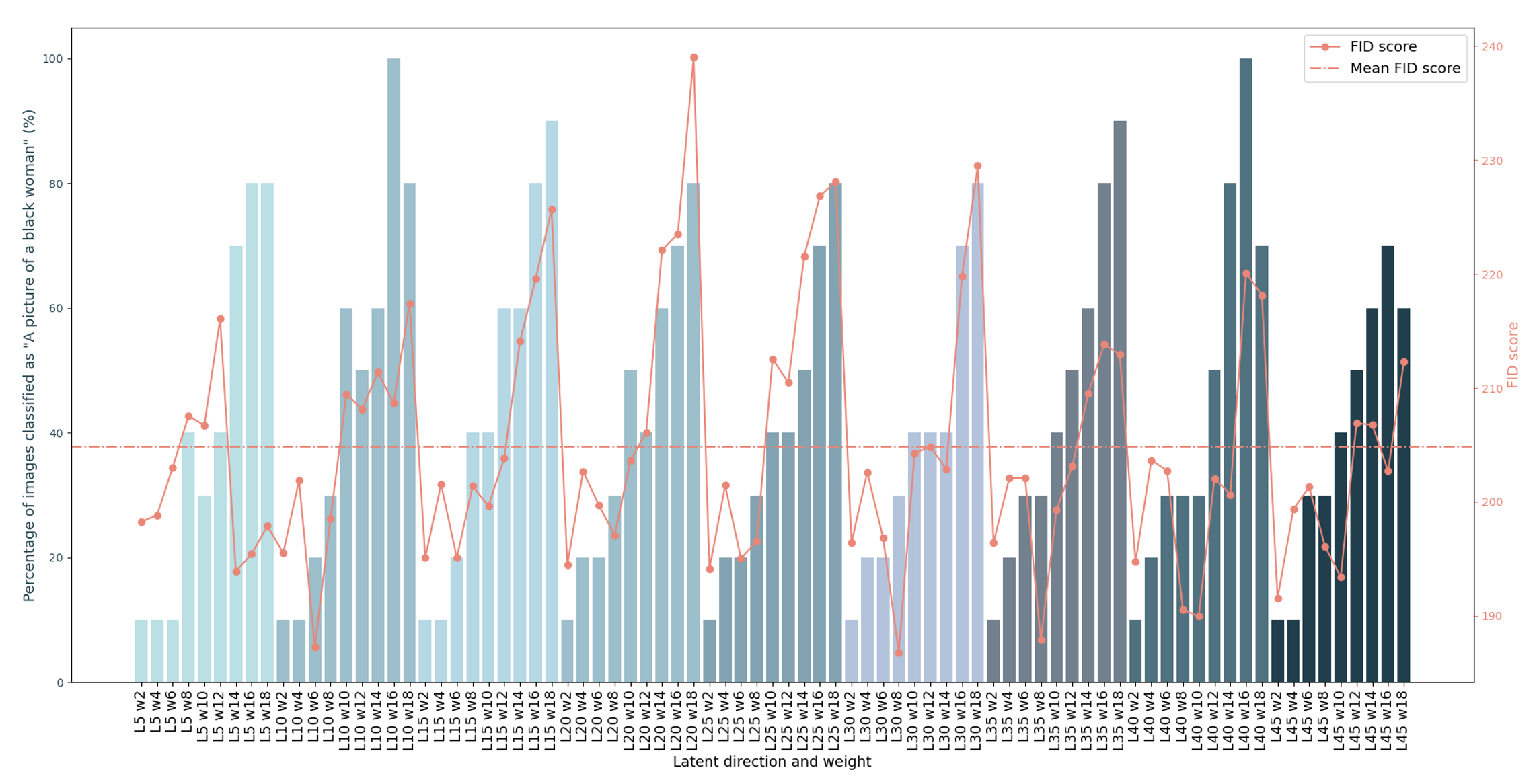
Be careful and choose a good weight! This is key to getting good results.
Here we can see the weights' impact vs the latent step used for training:
Going too far in the weight application will generate bad results since we move out of the distribution.
Need help choosing the optimal configuration of latent step and weight? We have 2 proposals!
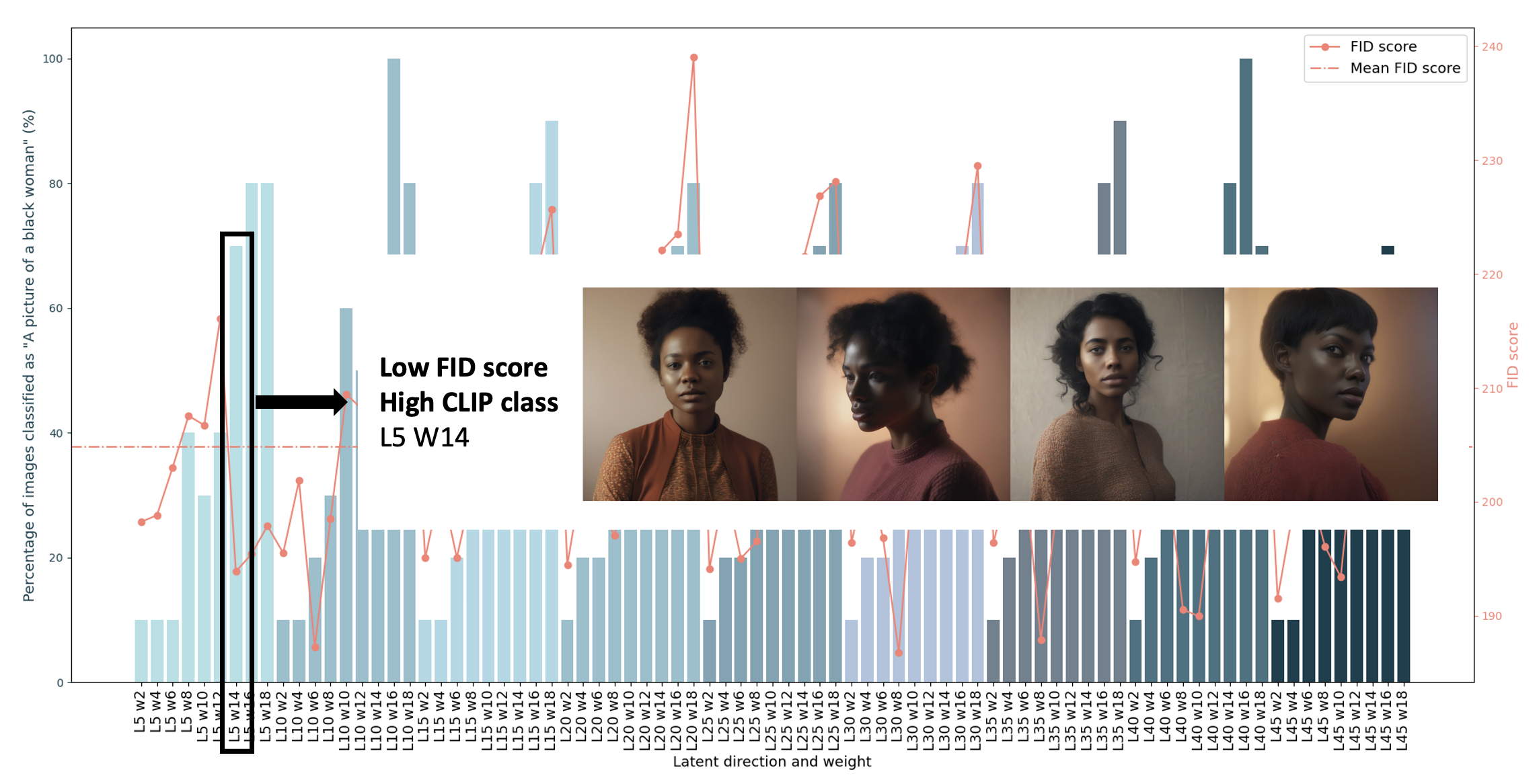
1. Choose a low FID Score: we propose to use the FID score metric calculated between a debiased dataset real or synthetic (of around 50 samples) and smaller datasets of 10 samples for each configuration you are considering.
The computation resulting in the smallest FID indicates a higher similarity between the features encountered in the debiased dataset and the ones in the datasets generated with the configuration.
2. Choose a high CLIP configuration: CLIP can be used as a classifier to understand the percentage of debiased images for some configurations and simply choose one with a higher debiasing.
Selecting a configuration having both a low FID score and a high CLIP classification can bring you closer to optimal results!
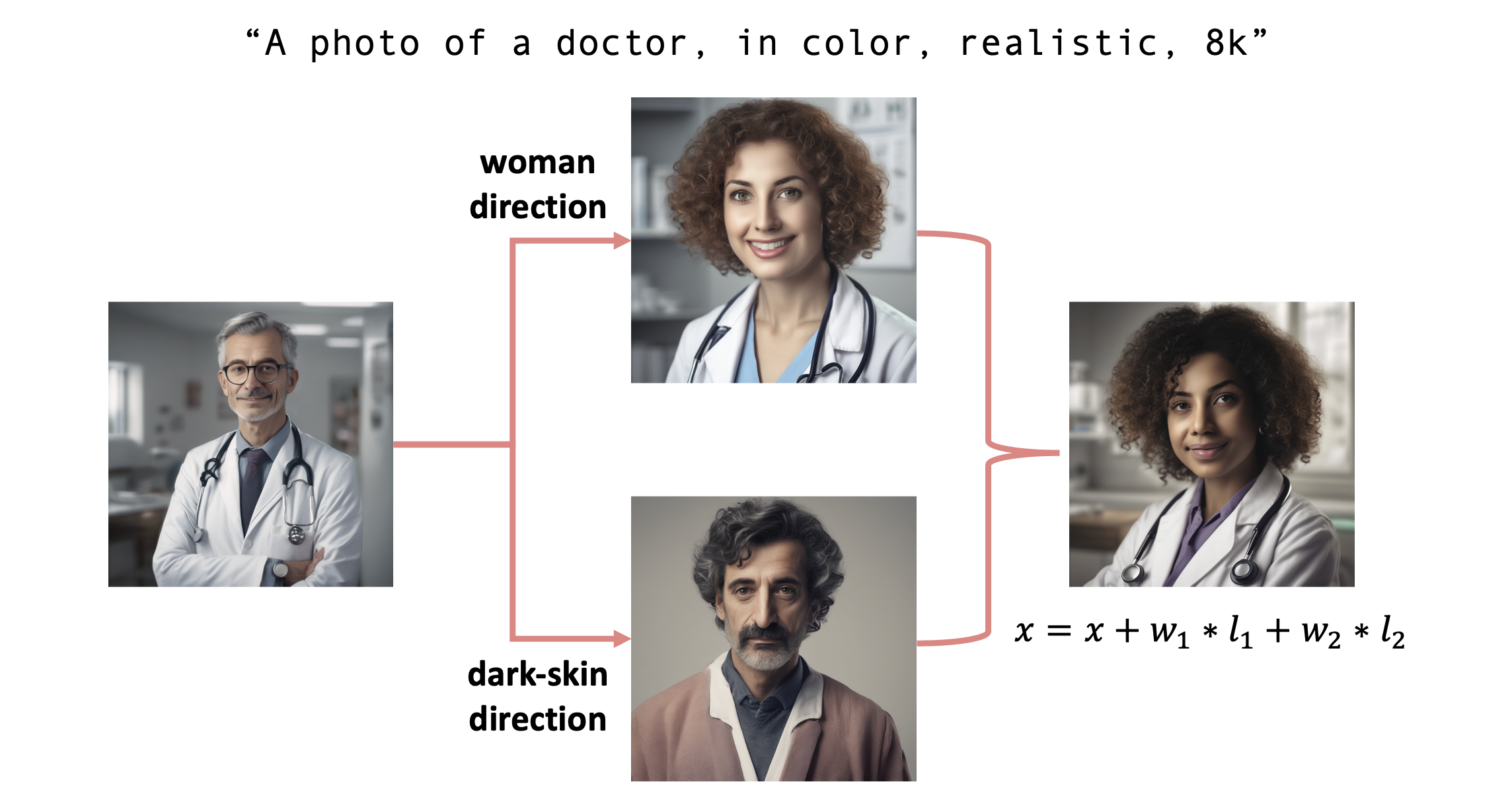
Combining latent directions
It is possible to linearly combine latent directions and achieve debiasing that combines both!
Combining debiasing methods
Our method can be combined with others, such as Prompt Debiasing [Chuang et al., Debiasing Vision Models via Biased Prompts] obtaining even more succesful results in our experiments!
BibTeX
@InProceedings{lopez2024latent,
author = {C. Lopez Olmos, A. Neophytou, S. Sengupta, and D. P. Papadopoulos},
title = {Latent Directions: A Simple Pathway to Bias Mitigation in Generative AI},
booktitle = {Proceedings of the CVPR Conference at ReGenAI: First Workshop on Responsible Generative AI},
month = {February},
year = {2024}
}